L'expression de l'information génétique
Fiche
Il existe dans nos cellules une information contenue dans l'ADN qui définit la manière dont notre corps est construit et dont il fonctionne.Cette information est transmise de génération en génération, c'est pourquoi on l'appelle l'information génétique.
Nous allons voir dans ce chapitre comment cette information s'exprime, c'est-à-dire comment, dans une cellule, on passe de l'information à sa réalisation concrète.
Si on prend une métaphore, l'information génétique est comme un plan d'architecte pour une maison. Pour réaliser le plan de l'architecte, il faudra des matériaux de construction, des ouvriers et des techniques de construction.
Nous allons donc chercher à voir dans une cellule quels sont les matériaux, quels sont les « ouvriers » et de quelle manière une cellule est « construite » d'après les « plans » de l'ADN.
Il sera question dans ce chapitre de différentes molécules comme les protéines ou les ARN.
Nous allons voir dans ce chapitre comment cette information s'exprime, c'est-à-dire comment, dans une cellule, on passe de l'information à sa réalisation concrète.
Si on prend une métaphore, l'information génétique est comme un plan d'architecte pour une maison. Pour réaliser le plan de l'architecte, il faudra des matériaux de construction, des ouvriers et des techniques de construction.
Nous allons donc chercher à voir dans une cellule quels sont les matériaux, quels sont les « ouvriers » et de quelle manière une cellule est « construite » d'après les « plans » de l'ADN.
Il sera question dans ce chapitre de différentes molécules comme les protéines ou les ARN.
Les notions de génotype et phénotype
L'information génétique qui définit un individu est ce qu'on appelle son génotype.La réalisation concrète du génotype, l'individu, est le phénotype.
Comment passe-t-on de l'un à l'autre ?
Le génotype est contenu dans l'ADN.
Le phénotype, lui, est constitué de lipides, glucides et protides.
Entre deux individus de la même espèce, ce sont surtout les protéines qui varient.
Nous allons donc chercher à savoir comment l'on passe de l'ADN aux protéines.
La transcription de l'ADN
L'ADN est contenu dans le noyau. C'est sur cet ADN que l'on trouve les gènes.Chaque gène est une information pour un caractère. C'est aussi un morceau d'ADN précis situé sur un chromosome précis.
Schéma d'un gène sur l'ADN
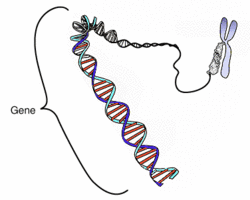 |
Un gène a un début et une fin, qui sont codés par des séquences de nucléotides particulières.
Le début d'un gène est reconnu par une enzyme particulière : l'ARN-polymérase.
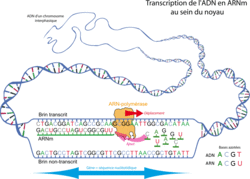
L'ARN-polymérase prend pour modèle un des deux brins de l'ADN, le brin transcrit.
Elle copie ce brin en associant des nucléotides d'ARN aux nucléotides d'ADN du brin transcrit. Le brin d'ARN produit est une copie du gène situé sur l'ADN, on l'appelle ARN messager ou ARNm.
Le brin qui ne sert pas de modèle pour la copie est appelé le brin non transcrit ou brin codant, car il possède la même séquence que l'ARNm synthétisé.
Rappel : dans l'ARN, le ribose remplace le désoxyribose et l'uracile remplace la thymine. Les ARN sont aussi généralement simple brin (on dit aussi monocaténaire) là où l'ADN est généralement double brin (ou bicaténaire).
=> La copie est appelée ARN messager ou ARNm.
Le début d'un gène est reconnu par une enzyme particulière : l'ARN-polymérase.
L'ARN-polymérase prend pour modèle un des deux brins de l'ADN, le brin transcrit.
Elle copie ce brin en associant des nucléotides d'ARN aux nucléotides d'ADN du brin transcrit. Le brin d'ARN produit est une copie du gène situé sur l'ADN, on l'appelle ARN messager ou ARNm.
Le brin qui ne sert pas de modèle pour la copie est appelé le brin non transcrit ou brin codant, car il possède la même séquence que l'ARNm synthétisé.
Rappel : dans l'ARN, le ribose remplace le désoxyribose et l'uracile remplace la thymine. Les ARN sont aussi généralement simple brin (on dit aussi monocaténaire) là où l'ADN est généralement double brin (ou bicaténaire).
=> La copie est appelée ARN messager ou ARNm.
La transcription
 |
Une fois formé, l'ARNm sort du noyau par des canaux qui traversent sa double enveloppe : les pores nucléaires.
L'ARNm se trouve alors dans le cytoplasme et l'étape suivante commence : la traduction.
L'ARNm se trouve alors dans le cytoplasme et l'étape suivante commence : la traduction.
La traduction de l'ARNm
Description de son déroulement
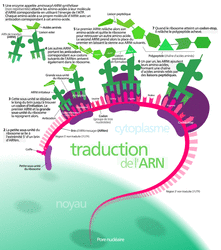
Une fois dans le cytoplasme, de petits organites, les ribosomes, viennent se fixer sur l'ARNm.
Les ribosomes sont de gros complexes moléculaires formés de deux sous-unités, une petite et une grosse, qui viennent « prendre en sandwich » l'ARNm. Chaque sous-unité est composée de nombreuses protéines et de petits ARN particuliers, les ARN ribosomiaux (ARNr).
Un ribosome commence par se fixer sur un codon (= un groupe de trois nucléotides) particulier de l'ARNm, le codon d'initiation (qui est toujours composé des nucléotides AUG).
À cet endroit, le ribosome fixe par complémentarité avec le codon d'initiation un autre ARN particulier, l'ARN de transfert ou ARNt. À cet ARNt est couplé un acide aminé particulier.
Par exemple, le codon d'initiation est AUG. L'ARNt qui y sera fixé possédera donc une séquence TAC complémentaire et sera couplé à un acide aminé qui sera toujours la méthionine (Met).
C'est la première étape de la traduction : l'initiation.
Puis, le ribosome se déplace de codon en codon (et donc se décale de trois nucléotides en trois nucléides le long de l'ARNm) et fait correspondre à chaque codon un ARNt et donc un acide aminé précis.
Le ribosome attache chaque acide aminé ajouté à ceux déjà fixés. Le ribosome construit donc une protéine à partir de l'information portée par les nucléotides de l'ARNm en faisant correspondre un acide aminé particulier à chaque codon de trois nucléotides.
Cette étape de la traduction est l'élongation.
Remarque : assez souvent, on observe que plusieurs ribosomes se suivent le long de l'ARNm, et que chacun fabrique une protéine. C'est ce qu'on appelle un polysome.
Finalement, le ribosome arrive à un codon stop sur l'ARNm.
Les deux sous-unités du ribosome se détachent de l'ARNm et libèrent la protéine synthétisée.
Cette ultime étape de la traduction est la terminaison.
La protéine synthétisée ainsi va se replier spontanément en une forme qui lui permettra de jouer son rôle dans la cellule.
Les ribosomes sont de gros complexes moléculaires formés de deux sous-unités, une petite et une grosse, qui viennent « prendre en sandwich » l'ARNm. Chaque sous-unité est composée de nombreuses protéines et de petits ARN particuliers, les ARN ribosomiaux (ARNr).
Un ribosome commence par se fixer sur un codon (= un groupe de trois nucléotides) particulier de l'ARNm, le codon d'initiation (qui est toujours composé des nucléotides AUG).
À cet endroit, le ribosome fixe par complémentarité avec le codon d'initiation un autre ARN particulier, l'ARN de transfert ou ARNt. À cet ARNt est couplé un acide aminé particulier.
Par exemple, le codon d'initiation est AUG. L'ARNt qui y sera fixé possédera donc une séquence TAC complémentaire et sera couplé à un acide aminé qui sera toujours la méthionine (Met).
C'est la première étape de la traduction : l'initiation.
Puis, le ribosome se déplace de codon en codon (et donc se décale de trois nucléotides en trois nucléides le long de l'ARNm) et fait correspondre à chaque codon un ARNt et donc un acide aminé précis.
Le ribosome attache chaque acide aminé ajouté à ceux déjà fixés. Le ribosome construit donc une protéine à partir de l'information portée par les nucléotides de l'ARNm en faisant correspondre un acide aminé particulier à chaque codon de trois nucléotides.
Cette étape de la traduction est l'élongation.
Remarque : assez souvent, on observe que plusieurs ribosomes se suivent le long de l'ARNm, et que chacun fabrique une protéine. C'est ce qu'on appelle un polysome.
Finalement, le ribosome arrive à un codon stop sur l'ARNm.
Les deux sous-unités du ribosome se détachent de l'ARNm et libèrent la protéine synthétisée.
Cette ultime étape de la traduction est la terminaison.
La protéine synthétisée ainsi va se replier spontanément en une forme qui lui permettra de jouer son rôle dans la cellule.
La traduction
 |
Le code génétique
Le code génétique est la correspondance qu'il y a entre la séquence en nucléotides de l'ADN (et de l'ARNm) et celle en acides aminés des protéines.La correspondance se fait entre trois nucléotides (ce qu'on appelle un triplet ou un codon) d'une part et un acide aminé d'autre part.
Le tableau qui donne la correspondance est le suivant :
Le code génétique
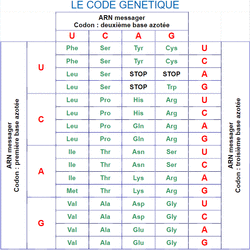 |
On voit qu'il existe 64 triplets de nucléotides différents. Mais il n'existe que vingt acides aminés différents dans les protéines.
En conséquence, certains triplets codent le même acide aminé.
Exemple : CUU et CUC codent tous les 2 pour l'aa Leu (Leucine).
C'est pourquoi on dit que le code génétique est redondant.
De plus, il existe des codons spéciaux :
En conséquence, certains triplets codent le même acide aminé.
Exemple : CUU et CUC codent tous les 2 pour l'aa Leu (Leucine).
C'est pourquoi on dit que le code génétique est redondant.
De plus, il existe des codons spéciaux :
- Le codon AUG est le codon d'initiation. C'est celui sur lequel le ribosome commence par se fixer lors de la traduction.
- Les trois codons stop ou codons de terminaison qui sont UAA, UAG et UGA. Ces codons entraînent le décrochement du ribosome quand celui-ci les « lit » sur l'ARNm.
© 2000-2025, Miscellane